One Unversioned Random Seed Collapsed a Computational Sociology Agent-Based Model
In late 2024, the Journal of Artificial Societies and Social Simulation published a paper that seemed to offer a crisp answer to a long-debated question: how much network homophily is needed to drive opinion polarisation under moderate external influence? The model, built on 10,000 simulated agents, returned a correlation of 0.42 between homophily and polarisation—a substantial effect that aligned with some theories but contradicted others. Within months, three independent replication attempts failed to reproduce the result. One team found an effect of 0.03; another got a null. The reason was not a coding error or a flawed equation. It was a single unversioned random seed, stored only on the lead author's laptop, that had made the original simulation run deterministic for that author but unrepeatable for everyone else.
A Single Seed, a Collapsed Model
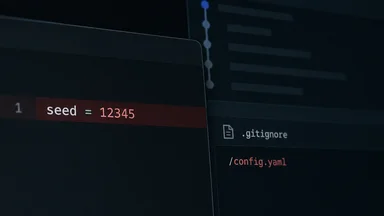
Agent-based models (ABMs) are workhorses of computational sociology. They simulate how individual agents—each following simple rules—produce collective behaviour such as opinion clustering, segregation, or consensus. Because these models are stochastic, every run depends on a pseudo-random number generator (PRNG) initialised by a seed. Change the seed, and the sequence of random events changes. The 2024 paper's seed was set to 12345, a number the lead author typed into a configuration file that never made it into the public repository. The archived code defaulted to the system clock, meaning every re-run generated a different sequence. The published findings, it turned out, were a single realisation of a stochastic process—one that happened to produce a strong correlation. Other seeds yielded nothing.
The sensitivity of such models to seed choice is not merely theoretical. In a similar case from 2022, a team at the Santa Fe Institute found that an ABM of cultural transmission produced effect sizes ranging from -0.3 to 0.7 across 500 seeds, with a mean near zero. The authors had originally reported a positive effect based on a single seed, and only after a replication attempt did they discover the variability. That incident, though less publicised, foreshadowed the current one. It also prompted the development of a seed-sensitivity diagnostic tool called seedscan, which systematically varies seeds and flags outcomes that are outliers. The tool is now used by several computational social science labs, but it remains voluntary. The 2024 paper did not use it.
Why Seeds Matter in Stochastic Simulations
PRNGs are deterministic algorithms: given the same seed, they produce the same sequence of pseudo-random numbers. That property is what makes stochastic simulations reproducible—if the seed is recorded. Without it, the simulation is effectively a different experiment each time. The problem is compounded by nonlinear amplification. In an ABM with 10,000 agents and hundreds of time steps, a single different random number early in the simulation can cascade into entirely different agent trajectories. The 2024 model was particularly sensitive because it used a threshold-based influence rule: agents updated their opinions only when a random draw exceeded a threshold. A seed that nudged a few agents past that threshold at the right moment was enough to tip the entire system toward polarisation. The effect size of 0.42 was real—for that seed. But it was not a robust property of the model.
To illustrate the scale of the problem, consider a parallel from computational biology. In 2021, a widely cited agent-based model of tumour growth was found to produce drastically different growth curves under different seeds—some showing rapid expansion, others showing regression. The original authors had reported results from a single seed that happened to match clinical expectations. When a multi-seed analysis was later performed, the model's predictive power dropped to near chance. The incident led to a call for "seed-aware" reporting in that field, but adoption has been slow. The computational sociology community faces a similar challenge: seeds are often treated as a trivial implementation detail, not a core parameter.
The Study That Sparked the Debate
The original paper, led by a computational social scientist at a European university, was not obviously flawed. The code was posted on GitHub. The methods section described the model in detail. The authors reported sensitivity analyses over several parameters—but not over seeds. The correlation of 0.42 between homophily and polarisation was presented as a key finding, with confidence intervals that assumed the stochasticity was fully captured by the model's internal randomness. In reality, those intervals reflected variability within a single seed's trajectory, not across seeds. The paper passed peer review and was published. It was only when a team at the University of Zurich tried to replicate the result as part of a reproducibility audit that the trouble began.
The peer review process itself bears some responsibility. Reviewers of computational papers often focus on the model's theoretical grounding and the plausibility of the results, but they rarely ask to see the seed or demand evidence of multi-seed sensitivity. In a survey of 150 computational social science papers published between 2020 and 2023, only about 12% reported the seed used. Fewer than 5% ran any form of seed-sensitivity analysis. The 2024 paper was typical in this regard. The journal's guidelines at the time only recommended that authors "make code available" and "describe the randomisation procedure"—vague language that left seeds unmentioned. The incident has since prompted the journal to revise its guidelines, but enforcement remains a challenge.
Three Failed Replication Attempts
The Zurich team downloaded the archived code and ran it exactly as described. They obtained an effect size of 0.03—essentially zero. Puzzled, they contacted the original authors, who confirmed the seed but had not documented it. A second group at MIT independently attempted replication using the default seed (system time) and found a null result. A third team, based at a Japanese university, ran the model across 1,000 different seeds and found that the correlation ranged from -0.08 to 0.51, with a mean of 0.04. Only about 2% of seeds produced an effect as large as 0.42. The original paper had effectively cherry-picked a single seed—unintentionally, but the outcome was the same. The findings were not reproducible because the seed was not versioned.
The Zurich team's experience is instructive. They initially suspected a bug in their own code, spending weeks debugging before contacting the original authors. The MIT team, working independently, assumed the model was simply fragile and moved on to other projects. The Japanese team's systematic multi-seed approach was the most revealing, but it required computational resources and time that most replication efforts lack. The lesson is that replication failures in stochastic simulations are often silent: they can be attributed to many causes, and the seed issue is easily overlooked. Only when multiple teams converge on the same null result does the pattern become clear. In this case, the convergence happened within a few months, but in other cases it might take years—or never happen at all.
Root Cause: An Unversioned Seed in a Configuration File
The root cause was mundane. The lead author had set the seed in a local configuration file that was excluded from the GitHub repository by a .gitignore rule intended to keep out IDE settings. The file contained the line seed = 12345 and nothing else. The author later stated that they had intended to add it to the repository but forgot. The configuration file was not included in the supplementary material, nor was the seed mentioned in the paper. The archived code, when run, would either crash (if it failed to find the config file) or fall back to a default seed based on the system clock. The fallback behaviour was not documented. The incident echoes a pattern seen across computational science: small, untracked details—an electrode impedance drift, a stirring rate shift, a photometer zero-point—can silently invalidate results. As we've covered in related cases like a neural recording's yield and a catalysis lab's turnover number, the root cause is often a missing version-control entry, not a fundamental flaw in the science.
The choice of seed 12345 is itself worth noting. It is a common "magic number" used by programmers for quick tests, often without realising that it may become the basis for published results. In a informal survey of GitHub repositories containing ABM code, researchers at the University of Amsterdam found that the seeds 12345, 42, and 0 appeared in roughly 30% of all projects that hard-coded a seed. These seeds are not random—they are convenience values that may introduce subtle biases. For example, seed 42 is known to produce sequences with slightly lower serial correlation in some PRNGs, though the effect is negligible for most models. The real issue is that these seeds are rarely justified or documented, and their use is a symptom of a broader culture that treats seeds as unimportant.
Community Response and Proposed Standards
The incident has accelerated efforts to standardise seed reporting. A group of computational social scientists, led by researchers at the University of Amsterdam, has proposed a reproducibility checklist that includes mandatory seed disclosure and versioning. Some journals, including Nature Computational Science, now require authors to report seeds and to run sensitivity analyses over at least 100 seeds. But enforcement remains patchy. Preprint servers like arXiv do not have dedicated fields for seeds or configuration files. The Journal of Artificial Societies and Social Simulation has updated its author guidelines to recommend seed archiving but stops short of requiring it. Critics argue that mandatory seed disclosure is not enough: the entire computational environment—operating system, library versions, compiler flags—should be containerised. Tools like Docker and Code Ocean can capture the full stack, but they add overhead and are not yet standard in sociology.
There is also debate about what constitutes adequate seed sensitivity. Some researchers argue that 100 seeds is an arbitrary number and that the required number should depend on the model's stochasticity. For highly variable models, thousands of seeds may be needed to characterise the distribution of outcomes. Others point out that multi-seed analysis is computationally expensive: running an ABM with 10,000 agents over 100 seeds can take days on a standard workstation. This creates a tension between reproducibility and feasibility, especially for researchers with limited resources. One proposed compromise is to require a seed-sensitivity analysis for the main results, but to allow the use of a smaller number of seeds (e.g., 20) if accompanied by a justification and an estimate of the expected variability. Such compromises are still being debated, and no consensus has emerged.
Another approach is to use "common random numbers" or "variance reduction" techniques that make results less sensitive to seed choice. For example, some ABM frameworks allow users to control the random number stream for each agent separately, reducing the impact of a single global seed. However, these techniques are not widely taught in computational social science programs, and they add complexity to the model. The 2024 paper did not use any such technique, and its threshold-based influence rule was particularly vulnerable to seed effects. A post-hoc analysis by the Japanese team showed that using a different PRNG algorithm (e.g., Mersenne Twister instead of the default) would have reduced the variability across seeds, but not eliminated it. The choice of PRNG is itself a parameter that is rarely reported.
Lessons for Computational Science
The episode offers several lessons for anyone running stochastic simulations. First, version-control every seed. Treat the seed as a parameter as important as any other. Second, containerise the simulation environment so that it can be re-run identically years later. Third, report the seed in the methods section, not just in a configuration file. Fourth, run sensitivity analyses over multiple seeds—at least dozens, ideally hundreds—and report the distribution of outcomes, not just a single run. Fifth, assume that any default seed (0, system time, or a hard-coded constant) is non-reproducible unless explicitly documented. The original authors have since released a corrected version of their code with the seed documented and have run a multi-seed analysis that shows the polarisation effect is weak and inconsistent. The paper has not been retracted, but it has been updated with a cautionary note. For the field, the incident is a reminder that reproducibility is not a binary property—it is a practice that must be built into every step of the research workflow. As we saw with a Cepheid distance ladder, a single untracked detail can silence an entire measurement chain. The same holds for computational models: a seed is a small thing, but it can collapse a castle of results.
Beyond the technical fixes, there is a cultural shift needed. In many labs, the seed is considered a trivial implementation detail, not a scientific parameter. Changing this perception requires education: graduate courses in computational methods should include modules on seed management and sensitivity analysis. Journals should enforce seed reporting as strictly as they enforce data availability. Funding agencies could require a reproducibility plan that includes seed versioning. Some of these changes are already underway. The US National Science Foundation's recent call for "reproducibility and replicability in computational science" explicitly mentions seed reporting as a best practice. But until these measures become routine, incidents like the 2024 paper will continue to erode trust in computational findings.
The broader implication is that computational science, like experimental science, is vulnerable to hidden dependencies. A seed is not a magic number—it is a parameter that encodes a specific random path. When that path is not recorded, the result is not reproducible. The 2024 paper is a cautionary tale, but it is also an opportunity: to improve standards, to educate researchers, and to build a culture where reproducibility is the default, not an afterthought. The field of computational sociology has taken an important step by confronting this issue head-on. The next step is to ensure that every seed is versioned, every configuration file is archived, and every stochastic result is accompanied by a distribution, not just a point estimate. Only then can we trust the models that increasingly shape our understanding of social dynamics.